Machine Learning Models: From Basics to Advanced Algorithms

Humans have already taught computers to write novels and music, issue loans, and even diagnose diseases. We'll discuss the different models of machine learning and how to choose the right one.
Machine Learning (ML) is a process in which a computer program, using artificial intelligence, learns to solve problems based on data. It identifies specific patterns and uses them to make decisions. The goal of machine learning is to increase the accuracy and speed of decision-making. The more detailed the introductory information that artificial intelligence receives, the more accurate the results will be.
What's Needed for Training
Data Science specialists are responsible for machine learning. They process data and build models for artificial intelligence. Here's what a specialist needs to be able to train machines:
- Structure information
- Think logically, analyze
- Know the Python programming language—algorithms for data processing are written in it
- Know Java and Scala—tools for data processing are written in these languages, which can be mastered during work
- Be proficient in SQL—it's a query language used to retrieve information from databases
- Know how to work with tools for working with databases—such as the Hadoop ecosystem for creating data lakes.
To train a machine, you need to first gather data based on which the computer will make decisions. This can be any information related to the object of modeling: numbers, images, or text. The task of a Data Science specialist is to understand what information is essential for analysis and what is not.
The first step is to study the object of modeling, its internal and external environment. It is necessary to understand how these three parameters interact. Similar to medicine, before making a diagnosis, it is essential to study the organism and the influence of external factors.
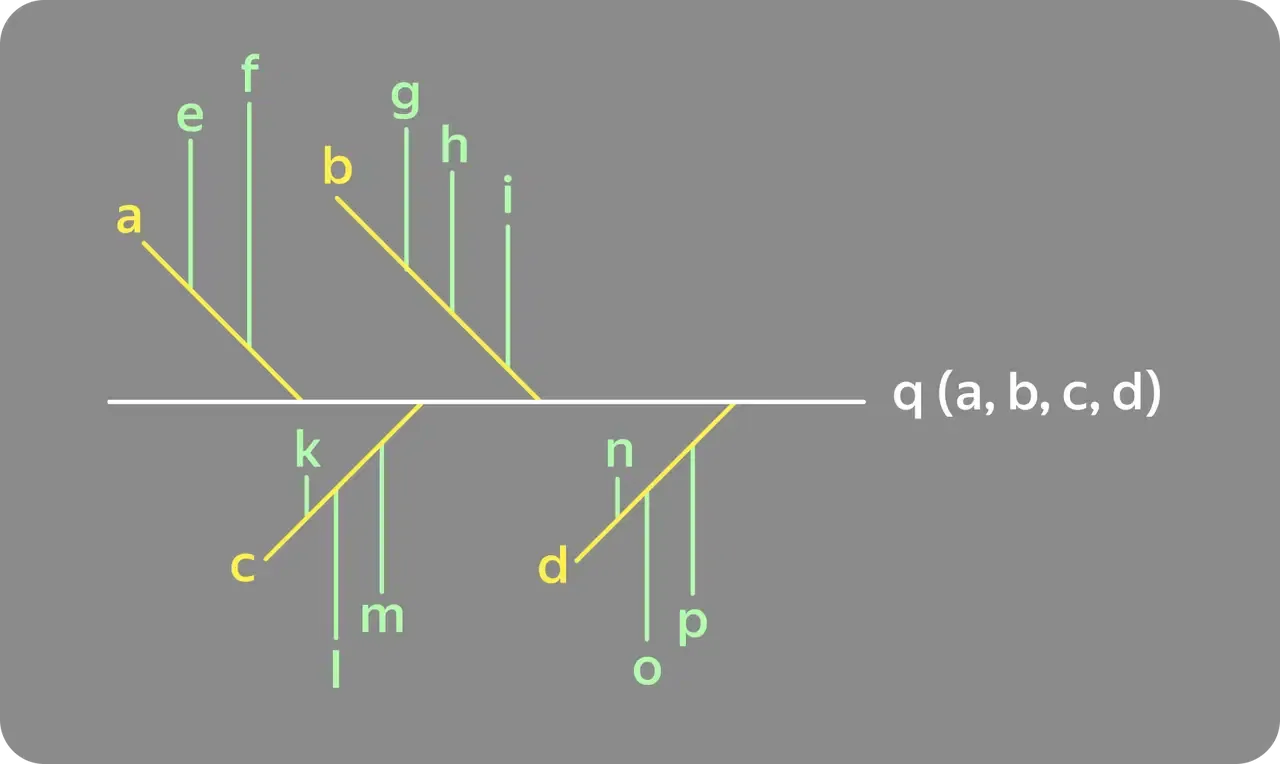
For analysis, you can use an Ishikawa diagram or the "fishbone" method: the diagram looks like a fish skeleton, where the head represents the problem, the tail is the output, the lower bones are facts, and the upper bones are the causes.
The process of working with data for machine learning goes through four stages:
- Data Collection: Gathering information related to the object of modeling.
- Exploration and Structuring of Data: In simpler terms, you need to show the machine correct and incorrect answers. For example, a system for recording violations on roads is initially trained on real cases.
- Data Preprocessing: A specialist reviews the information and corrects errors.
- Loading Data in the Form of Code into the Learning Model: Details about this will be discussed in the next section.
What Are Machine Learning Models
A machine learning model is a method of teaching a computer. The machine starts to think and act like a human, only more precisely. The method relies on data about the object: it is fed into the model, and the output is a forecast—a ready-made solution.
There are three types of ML models, each with its parameters for processing information:
- Supervised Learning: The computer is provided with a set of labeled data (dataset), based on which it finds solutions to problems.
- Unsupervised Learning: The model receives unlabeled data without evaluation and tries to find answers on its own.
- Reinforcement Learning: The machine makes decisions based on user actions, as seen in games like chess.
Machine learning models are also categorized based on the types of tasks they solve:
- Regression Models: Predict numerical characteristics of an object. For example, predicting the cost of an apartment based on its area or the number of people at the airport depending on the day of the week.
- Classification Models: Predict the category of an object based on predefined parameters. For instance, diagnosing a patient based on medical history, test results, and symptoms.
- Regression-Classification Models: Capable of solving both types of tasks.
Types of Machine Learning Models
Let's explore examples of supervised machine learning models. Each of them can be used for different purposes, meaning the same task can be solved in various ways.
Linear Regression (Regression Model)
Shows the relationship between several variables—how the outcome Y depends on one or more variables x. It works when there is a linear relationship between the parameters and the outcome.
For example, with three variables: the quantity of sold goods, the day of the week, and the air temperature. Based on this data, a regression model can forecast how much ice cream to purchase from the supplier for the next week.
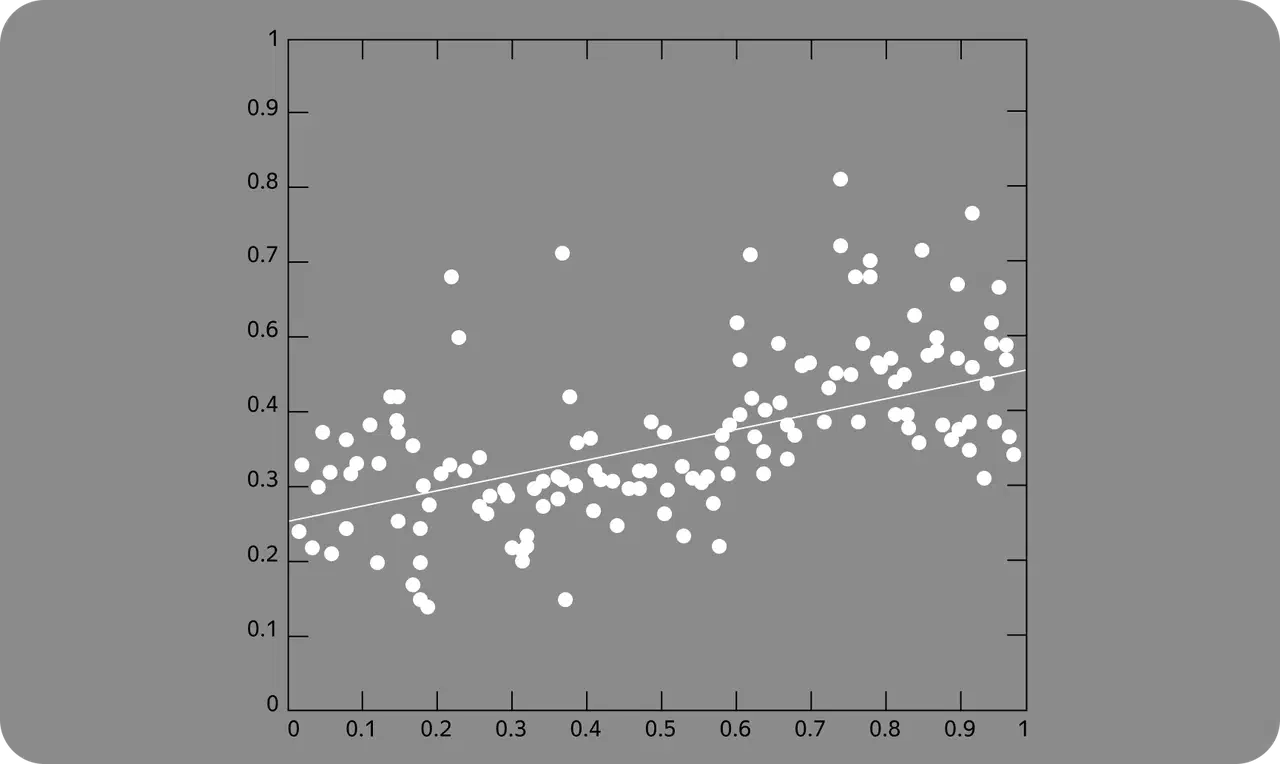
Logistic Regression (Classification Model)
Demonstrates the relationship between variables and their outcome in linear dependence. Unlike linear regression, the dependent variable has only two values, such as yes/no or 1/0.
In a scenario where a patient calls a clinic's call center, an automated system assigns numbers and conditions to them: 1—dentistry, 2—pediatrics, 3—adult department, 4—operator consultation. If the patient presses "2," they are given a new set of options: 1—schedule a consultation, 2—get a certificate, 3—cancel the appointment, and so on until the client achieves the desired result.
Regression-Classification Models
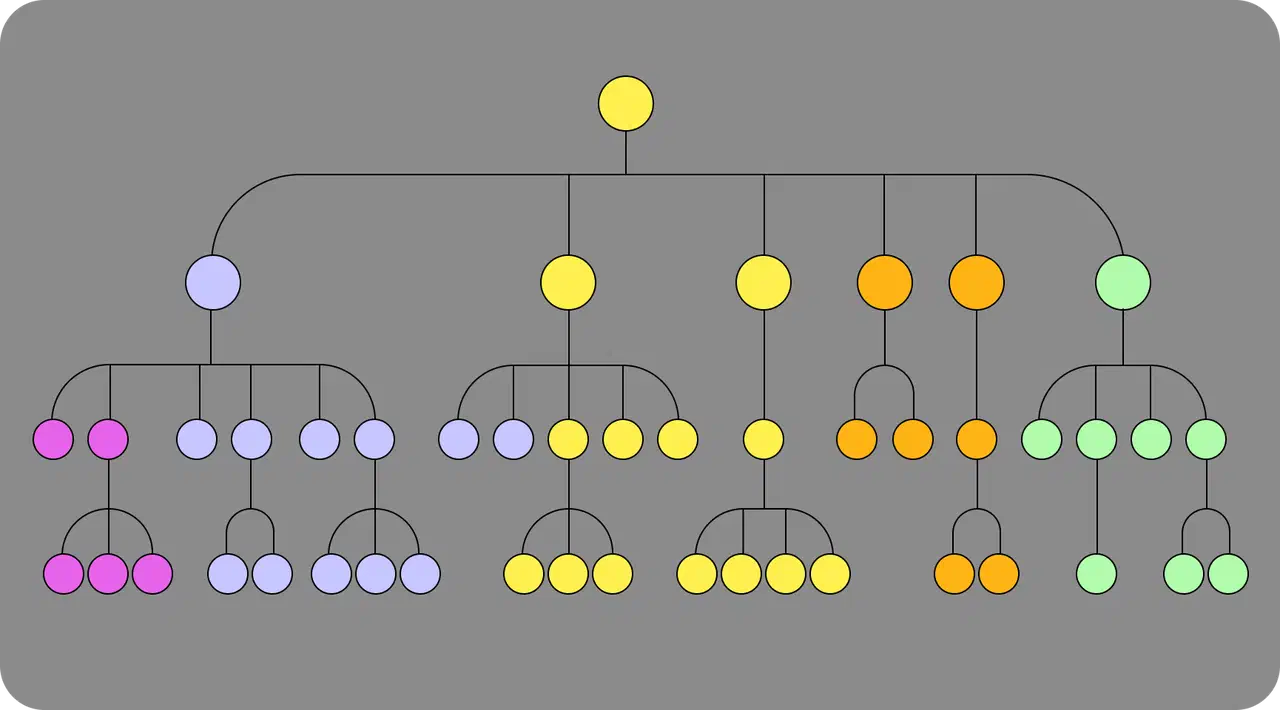
Decision Tree:
In this model, decision-making depends on "nodes" and "leaves." At the top of the decision tree is the initial node, where the entire sample goes. Then, it is checked for a condition or the presence of a feature. This process continues until a result is obtained.
This model is used, for example, in a bank to decide whether to approve a loan or not. If the client's age is less than 18, the algorithm outputs "no." If the age is 18 and above, the algorithm outputs "yes" and moves on to the next parameter—income level, and so on.
Random Forest Model:
A more advanced version of the "Decision Tree" model—requiring less tuning. It consists of several decision trees connected to each other.
This model can be used to analyze health data and factors that may influence illness: age, weight, gender. It builds multiple decision trees, each determining the importance of a specific factor in predicting illness.
Naive Bayes Classifier:
Based on Bayes' theorem, it helps understand how event X will occur if the associated event Y happens. In Bayesian classification, X is the class of the object, and Y is its feature. The model's drawback lies in its assumption that objects are conditionally independent, which may not be true in reality.
To determine which of the emails are fraudulent and which are not, a regression model analyzes the email, produces two results—"spam" or "not spam," and sorts the emails accordingly.
K-Nearest Neighbors:
A popular and easy-to-use model, although it performs poorly with large volumes of data. The essence is to assign properties of neighboring objects, whose properties are already known, to the object being modeled.
With a database of user preferences in an online store, the KNN model can predict which product might interest a specific customer. The model searches for users with similar preferences and recommends products they liked.
AdaBoost:
During training, it builds a composition of basic algorithms to enhance their effectiveness. The idea is that each subsequent classifier is built on objects poorly classified by the previous ones.
This is how facial recognition systems are created: AdaBoost designs several classifiers trained on data containing facial images. Each classifier aims to improve the accuracy of predictions made by the preceding classifier.
XGBoost:
Constructed as an ensemble of weak predictive models, it calculates deviations from the predictions of an already trained ensemble at each new training stage. The next iteration added to the ensemble will predict these deviations.
This model can be used for working with financial data and analyzing fundamental company data, such as revenues, expenses, and profitability.
Support Vector Machines (SVM):
Suitable for solving classification and regression tasks (relationships between variables). It constructs a hyperplane that optimally separates objects in the sample. The greater the distance between the separating hyperplane and the objects, the lower the average classification error.
For example, classifying brain images based on MRI scans. The method can be trained on numerous features (tumor size, shape, and tissue texture) and used to categorize images into two categories: healthy and diseased.
Artificial Neural Networks:
Mimicking the human brain's operation, it consists of layers of interconnected nodes (neurons) that can learn to associate input data with output through a process.
The choice of machine learning model depends on two factors:
- Input Data: It can be numerical or categorical—in the form of text. The object of modeling can also be numerical or textual.
- Data Volume: For example, for large amounts of information, it doesn't make sense to use logistic regression.
The choice of a model depends on the structure, size, and quality of the data. The modeling outcome is also influenced by these factors: if the data is unverified or insufficient, the result will be ineffective. It's possible to select one or several models and test them.



